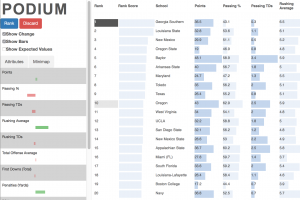
People often rank and order data items as a vital part of making decisions. Multi-attribute ranking systems are a common tool used to make such data-driven decisions. These systems are often table-based tools that can produce rankings based on numerical weights that a user assigns to each attribute, where the weight represents how important the user believes an attribute is to their decision. These systems assume that users are able to quantify their conceptual understanding of how important particular attributes are; however, this is not always the case. Users often have a more holistic understanding of the data. They form opinions that data point A is better than data point B but do not necessarily know what attributes are important.
To address these challenges, we present an application of SVM to infer attribute weights based on a user's interactions for the purpose of ranking multi-attribute data. We developed a prototype system, Podium, that allows users to drag rows in the table indicating where they think data items belong based on their knowledge or preferences. Our system then infers a weighting model using SVM that satisfies the user's preferences as closely as possible. Whereas past systems help users understand the relationships between data items based on changes to attribute weights, our approach helps users to understand the attributes that might inform their understanding of the data. Our approach allows users to explore their preferences and expose their biases.